Apache Spark
Apache Spark is an open source, general-purpose platform for cluster computing. Spark offers APIs in Java, Scala, Python, and R. Spark also provides higher-level tools to support SQL queries, streaming data, machine learning, and graph algorithms.
All code snippets are written in Python and use pyspark.
Clusters and Nodes
At its core, Spark is responsible for scheduling, distributing, and monitoring applications consisting of many computational tasks across many workers. Spark spreads data and computations over clusters with multiple nodes. Each node performs in-memory data processing. Spark enables parallel computation by giving each node a subset of the total data. Information in this section is taken from Spark's Cluster Node Overview.
A Spark application is coordinated by the Spark Context object of the main program (called the driver program). The Spark Context communicates with a cluster manager (or master). The cluster manager sends application code, input data, and tasks to a set of worker nodes (or slaves). Worker nodes start an executor that runs tasks and returns results.
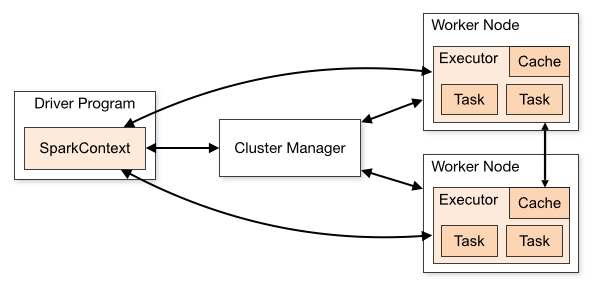
The driver program has a web UI, typically on port 4040, that displays information about tasks, executors, and storage.
Spark Context
The Spark Context is the main entry point for Spark functionality. A Spark
Context is essentially a client that tells Spark how to connect to the Spark
cluster. The special "local" string tells Spark to run in local mode.
sc = SparkContext("local", "example")
A SparkContext object may also be instantiated with SparkConf.
conf = SparkConf().setMaster("local").setAppName("example")
sc = SparkContext(conf=conf)
Running Applications
Use bin/spark-submit to launch applications on a cluster. See Submitting
Applications for more information.
# Run locally with 8 worker threads.
bin/spark-submit \
--master local[8] \
src/example.py \
10 # program argument
# Run against a standalone master server.
bin/spark-submit \
--master spark://207.184.161.138:7077 \
--executor-memory 5G \
src/example.py \
10
Resilient Distributed Datasets (RDD)
Resilient Distributed Datasets (RDD) are the fundamental data structure of Spark. An RDD is a collection of elements partitioned across the nodes of the cluster. Note that Apache now recommends Datasets and DataFrames instead of the RDD interface. Information in this section is taken (often directly) from the RDD Programming Guide.
Create an RDD by parallelizing an existing collection or by referencing a dataset in an external storage system. All methods below take an optional second argument for controlling the number of file partitions.
# RDD from an existing collection.
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# RDD from a local file.
rdd = sc.textFile("data.txt")
# RDD from an S3 Bucket.
rdd = sc.textFile("s3a://bucket/file.txt")
RDDs support two types of operations: transformations (e.g. map) and
actions (e.g. reduce). All transformations in Spark are lazy;
transformations are only computed when an action requires a result.
# Count number of characters. rdd.map(len).reduce(lambda a, b: a + b)
Spark SQL
Spark SQL is a Spark module for structured data processing. Spark SQL is a higher level interface than the RDD API. The SQL module provides a DataFrame abstraction built on top of RDDs. This abstraction facilitates SQL operations and provides additional optimization. DataFrames require a Spark Session.
spark = SparkSession.builder.getOrCreate()
flights = spark.sql("FROM flights SELECT * LIMIT 10")
flights.show()
The sql method takes a query string and returns a DataFrame with the
results. List all available tables with spark.catalog.listTables().
A Spark DataFrame may created from an existing RDD, a file, or
programmatically. The SparkSession has a .read attribute which has several
methods for reading different data sources into Spark DataFrames.
airports = spark.read.csv("airports.csv")
DataFrames provide a domain-specific language for data manipulation. Methods
include select, filter, join, groupBy, and others. If the data can fit
in memory, a Spark DateFrame can be also be converted to a pandas DataFrame
using the .toPandas() method. spark.createDataFrame(..) does the reverse.
TODO Spark Streaming
TODO Spark ML
TODO Spark Graph
TODO Shared Variables: Broadcast, Accumulator
See Spark's documentation for more information.